Resumen
Objetivo de la Investigación
Determinar hasta qué punto un modelo bayesiano 1PL cuya distribución prior para la dificultad del ítem proviene de una predicción externa mejora la precisión de la estimación frente al método tradicional de Máxima Verosimilitud (MLE), considerando diferentes niveles de calidad del prior y tamaños muestrales.
Metodología
Tipo de estudio: Simulación Monte Carlo
Factores evaluados:
- Calidad del prior: Tres niveles de correlación entre predicción externa y parámetro verdadero (R² = 0.2, 0.5, 0.8)
- Tamaño muestral: Cuatro fracciones de la muestra completa (30%, 50%, 80%, 100% de 1,000 individuos)
Variable dependiente: Error cuadrático medio (MSE) de las estimaciones de parámetros
- Simulación de parámetros: Generación de parámetros verdaderos para habilidades (θ) y dificultades (β)
- Generación del prior: Creación de distribución prior basada en predicciones externas con diferentes niveles de precisión
- Simulación de respuestas: Generación de matrices de respuesta usando el modelo logístico 1PL
- Estimación MLE: Implementación del método de máxima verosimilitud tradicional
- Estimación Bayesiana: Implementación usando PyMC con prior informativo
- Evaluación comparativa: Cálculo de métricas de precisión y análisis estadístico
- Python: Lenguaje principal para análisis estadístico y modelado
- PyMC: Librería de programación probabilística para inferencia bayesiana
- Kedro: Framework para orquestación de pipelines de datos reproducibles
- Scikit-learn: Implementación de algoritmos de machine learning y MLE
- NumPy/SciPy: Computación científica y operaciones matriciales
Visualización del Pipeline de Análisis
Explorar Pipeline Interactivo
Accede a la visualización interactiva completa del pipeline para explorar dependencias y resultados en detalle.
Ver Pipeline InteractivoResultados Preliminares
Los primeros resultados del experimento muestran evidencia clara del deterioro en la precisión de las estimaciones de máxima verosimilitud conforme se reduce el tamaño de la muestra.
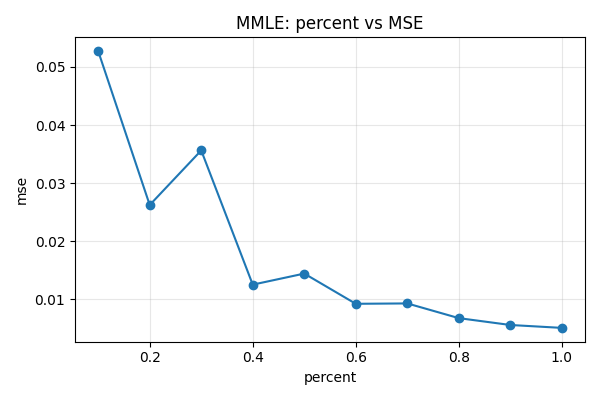
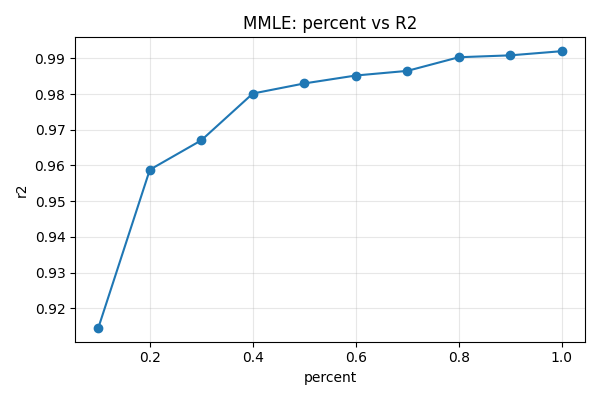
Los resultados preliminares confirman la hipótesis teórica sobre la degradación del rendimiento de MLE en condiciones de muestra limitada. Estos hallazgos establecen la línea base para evaluar si el enfoque bayesiano con prior informativo puede mitigar estas limitaciones.
Próximos análisis: Comparación directa con resultados bayesianos y evaluación del impacto de la calidad del prior en diferentes escenarios muestrales.
Estado Actual del Proyecto
Componentes Completados
- ✅ Implementación del pipeline de simulación con Kedro
- ✅ Módulo de estimación por máxima verosimilitud (MLE)
- ✅ Módulo de estimación bayesiana con PyMC
- ✅ Generación de datos sintéticos y submuestreo
- ✅ Análisis preliminar de resultados MLE
- ✅ Visualización del pipeline con Kedro-Viz
En Desarrollo
- 🔄 Implementación completa del modelo bayesiano con PyMC
- 🔄 Análisis comparativo entre métodos MLE y Bayesiano
- 🔄 Evaluación del impacto de la calidad del prior
- 🔄 Generación de reportes estadísticos del experimento completo
Planificado
- 📋 Análisis de sensibilidad de hiperparámetros
- 📋 Redacción del informe final